前天的趣味SQL, 經過大家熱烈的響應,有提到 width_bucket()
https://ithelp.ithome.com.tw/questions/10201169
今天我們就來介紹一下 width_bucket()
--------------------
-- Qucik Start Sample
with t1(n) as (
select generate_series(1, 10)
)
select n
, width_bucket(n,1,10,2)
, width_bucket(n,1,10,9)
from t1;
n | width_bucket | width_bucket
----+--------------+--------------
1 | 1 | 1
2 | 1 | 2
3 | 1 | 3
4 | 1 | 4
5 | 1 | 5
6 | 2 | 6
7 | 2 | 7
8 | 2 | 8
9 | 2 | 9
10 | 3 | 10
(10 rows)
with t1(n) as (
select generate_series(1, 100)
), t2 as (
select n
, width_bucket(n,1,101,4) "bucket_n"
from t1
)
select bucket_n
, min(n)::text || ' ~ ' || max(n)::text as "bucket_range"
from t2
group by bucket_n
order by bucket_n
;
bucket_n | bucket_range
----------+--------------
1 | 1 ~ 25
2 | 26 ~ 50
3 | 51 ~ 75
4 | 76 ~ 100
(4 rows)
--------
-- 邊界, 含低限 不含高限
with t1(n) as (
select generate_series(1, 3)
)
select n
, width_bucket(n,1,3,3)
, width_bucket(n,1,4,3)
from t1;
n | width_bucket | width_bucket
---+--------------+--------------
1 | 1 | 1
2 | 2 | 2
3 | 4 | 3
(3 rows)
-- 所以 1 ~ 3, 高限必須大於 3
-- 看 1 ~ 12 分三組
with t1(n) as (
select generate_series(1, 12)
)
select n
, width_bucket(n,1,12,3)
, width_bucket(n,1,13,3)
from t1;
n | width_bucket | width_bucket
----+--------------+--------------
1 | 1 | 1
2 | 1 | 1
3 | 1 | 1
4 | 1 | 1
5 | 2 | 2
6 | 2 | 2
7 | 2 | 2
8 | 2 | 2
9 | 3 | 3
10 | 3 | 3
11 | 3 | 3
12 | 4 | 3
-- Out of Range
with t1(n) as (
select generate_series(-2, 14)
)
select n
, width_bucket(n,1,13,3)
from t1;
n | width_bucket
----+--------------
-2 | 0
-1 | 0
0 | 0
1 | 1
2 | 1
3 | 1
4 | 1
5 | 2
6 | 2
7 | 2
8 | 2
9 | 3
10 | 3
11 | 3
12 | 3
13 | 4
14 | 4
(17 rows)
-------------
-- 1 ~ 10 分到 10個桶子, 可以用以下兩種方式.
with t1(n) as (
select generate_series(1, 10)
)
select n
, width_bucket(n,1,11,10)
, width_bucket(n,1,10,9)
from t1;
n | width_bucket | width_bucket
----+--------------+--------------
1 | 1 | 1
2 | 2 | 2
3 | 3 | 3
4 | 4 | 4
5 | 5 | 5
6 | 6 | 6
7 | 7 | 7
8 | 8 | 8
9 | 9 | 9
10 | 10 | 10
(10 rows)
-- 兩種結果看起來一樣.但是...
-- 我們來看 1 ~ 100, 分到 10 個 桶子.
with t1(n) as (
select generate_series(1, 100)
), t2 as (
select min(n) minn
, max(n) maxn
from t1
)
select width_bucket(n, minn, maxn+1, 10) bucket
, int4range(min(n), max(n), '[]') as range
, count(*)
from t2
, t1
group by bucket
order by bucket;
bucket | range | count
--------+----------+-------
1 | [1,11) | 10
2 | [11,21) | 10
3 | [21,31) | 10
4 | [31,41) | 10
5 | [41,51) | 10
6 | [51,61) | 10
7 | [61,71) | 10
8 | [71,81) | 10
9 | [81,91) | 10
10 | [91,101) | 10
(10 rows)
-- 因為 default 表示法是 [), 低含高不含
-- 所以 [1,10] 會表示成 [1,11)
with t1(n) as (
select generate_series(1, 100)
), t2 as (
select min(n) minn
, max(n) maxn
from t1
)
select width_bucket(n, minn, maxn, 9) bucket
, int4range(min(n), max(n), '[]') as range
, count(*)
from t2
, t1
group by bucket
order by bucket;
bucket | range | count
--------+-----------+-------
1 | [1,12) | 11
2 | [12,23) | 11
3 | [23,34) | 11
4 | [34,45) | 11
5 | [45,56) | 11
6 | [56,67) | 11
7 | [67,78) | 11
8 | [78,89) | 11
9 | [89,100) | 11
10 | [100,101) | 1
(10 rows)
-- 分 9 桶, 就是 每桶 11 個, 100 分到第 10 桶.
-- 所以比較好的方式是,桶數是我們想要的,高限略大的方式.
------------
-- 不等寬度分組, 例如一些 等第
-- 傳統方式可以使用 case when 語法 或是 建立對照表, 用 join 方式.
-- 在此就不舉例.
with t1(n) as (values
(40),(59),(60),(70),(75),(89),(99),(100),(101)
)
select n
, width_bucket(n, array[60, 70, 90, 101])
from t1;
n | width_bucket
-----+--------------
40 | 0
59 | 0
60 | 1
70 | 2
75 | 2
89 | 2
99 | 3
100 | 3
101 | 4
(9 rows)
-- 注意到 101 是 4, 60 是 1, 60以下是 0
---------------
-- 也可以用來做 時段分析.
-- 假設 0點到7點 可能因為這段的事件較少, 分成第一段.
-- 8點到18點 一小時分一段, 當然也可以分到更細,舉例就單純一點.
-- 18點到24點 每兩小時分一段.
create table it201122 (
id int generated always as identity
, ts timestamp not null
);
insert into it201122 (ts)
select 'yesterday'::timestamp + random() * interval '8 hours'
from generate_series(1, 500);
insert into it201122 (ts)
select '2020-11-21 08:00:00'::timestamp + random() * interval '10 hours'
from generate_series(1, 1e5);
insert into it201122 (ts)
select '2020-11-21 18:00:00'::timestamp + random() * interval '6 hours'
from generate_series(1, 2000);
commit;
-- 分小時統計,相信大家都很熟練了.
-- 用 width_bucket() 不同時段的方式.
with t1 as (
select extract(HOUR FROM ts)::integer as hour
from it201122
)
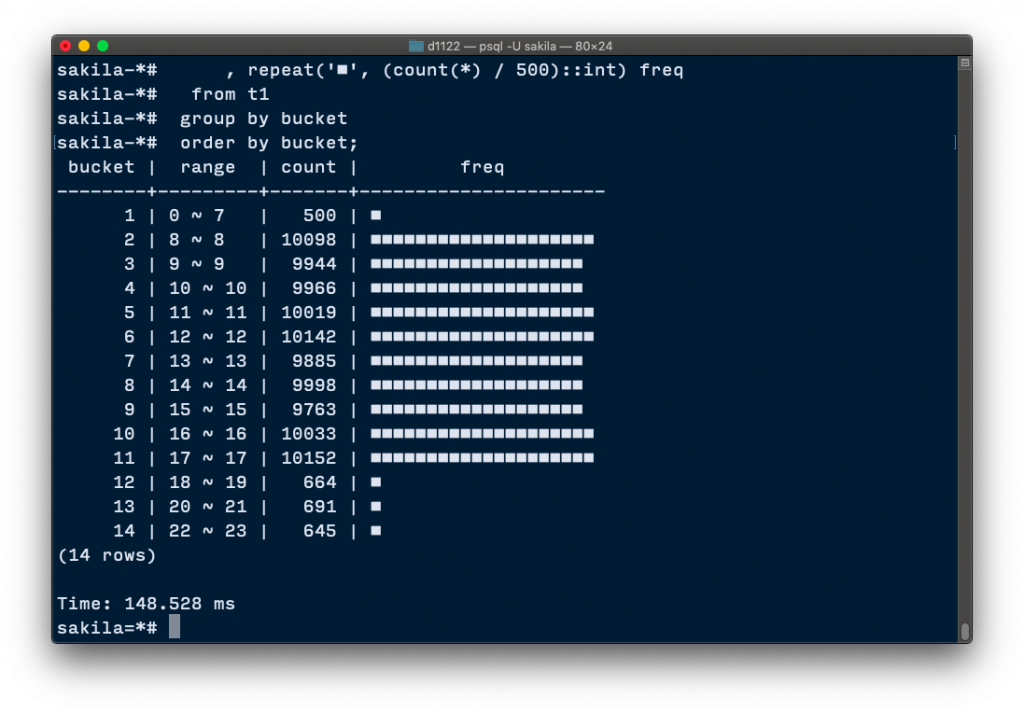
select width_bucket(hour, array[0, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 20, 22, 24]) bucket
, min(hour)::text || ' ~ ' || max(hour)::text as range
, count(*)
, repeat('■', (count(*) / 500)::int) freq
from t1
group by bucket
order by bucket;
bucket | range | count | freq
--------+---------+-------+----------------------
1 | 0 ~ 7 | 500 | ■
2 | 8 ~ 8 | 10098 | ■■■■■■■■■■■■■■■■■■■■
3 | 9 ~ 9 | 9944 | ■■■■■■■■■■■■■■■■■■■
4 | 10 ~ 10 | 9966 | ■■■■■■■■■■■■■■■■■■■
5 | 11 ~ 11 | 10019 | ■■■■■■■■■■■■■■■■■■■■
6 | 12 ~ 12 | 10142 | ■■■■■■■■■■■■■■■■■■■■
7 | 13 ~ 13 | 9885 | ■■■■■■■■■■■■■■■■■■■
8 | 14 ~ 14 | 9998 | ■■■■■■■■■■■■■■■■■■■
9 | 15 ~ 15 | 9763 | ■■■■■■■■■■■■■■■■■■■
10 | 16 ~ 16 | 10033 | ■■■■■■■■■■■■■■■■■■■■
11 | 17 ~ 17 | 10152 | ■■■■■■■■■■■■■■■■■■■■
12 | 18 ~ 19 | 664 | ■
13 | 20 ~ 21 | 691 | ■
14 | 22 ~ 23 | 645 | ■
(14 rows)
-- 若使用分小時的方式,有些時段的量太小,使用width_bucket()
-- 更靈活的讓我們來分析資料.
-- width_bukcet() 與 ntile() 的差異,我們將在之後再介紹.
 一級屠豬士
一級屠豬士
